Big shoutout to KASM for sponsoring this video. KASM workspaces supports the OSINT Community Efforts by providing the following products: Kasm Community Edition: https://kasmweb.com/community-edition Kasm Cloud OSINT: https://kasmweb.com/cloud-personal Kasm Workspaces OSINT Platform for Professionals/: https://kasmweb.com/osint Kasm Infrastructure/Apps for OSINT Collection: https://registry.kasmweb.com/1.0/ // MJ Banias’ SOCIALS // LinkedIn: / mjbanias Cloak and Dagger Podcast (Spotify): https://open.spotify.com/show/6mT8zDM… The Debrief: https://thedebrief.org/podcasts/ Instagram: / mjbanias X: https://x.com/mjbanias Website: https://www.bullshithunting.com/ // Ritu Gill’ SOCIALS // LinkedIn: / ritugill-osinttechniques OSINT Techniques website: https://www.osinttechniques.com/ Instagram: https://www.osinttechniques.com/ X: https://x.com/osinttechniques YouTube: / @forensicosint Forensic OSINT website: https://www.forensicosint.com/ TikTok: / osint.techniques // Rae Baker’s SOCIALS // Website: https://www.raebaker.net/ LinkedIn: linkedin.com/in/raebakerosint X: https://x.com/wondersmith_rae // Eliot Higgins’ SOCIALS // Bellingcat website: https://www.bellingcat.com/author/eli… X: https://x.com/eliothiggins // Books // The UFO People: A Curious Culture by MJ Banias: USA: https://amzn.to/3xP5Jme UK: https://amzn.to/4cOrzoK Deep Dive: Exploring the Real-world Value of Open Source Intelligence by Rae Baker and Micah Hoffman: USA: https://amzn.to/3xFN9gv UK: https://amzn.to/3zJSy6z We Are Bellingcat: Global Crime, Online Sleuths, and the Bold Future of News by Eliot Higgins: USA: https://amzn.to/3RXNa64 UK: https://amzn.to/4cvYP4B // YouTube video REFERENCE // Top 10 FREE OSINT tools (with demos): • Top 10 FREE OSINT tools (with demos) … Deep Dive OSINT: • Deep Dive OSINT (Hacking, Shodan and … Best Hacking Python Book: • Best Hacking Python Book? She Hacked Me: • She hacked me! // David’s SOCIAL // Discord: / discord X: / davidbombal Instagram: / davidbombal LinkedIn: / davidbombal Facebook: / davidbombal.co TikTok: / davidbombal YouTube: / @davidbombal // MY STUFF // https://www.amazon.com/shop/davidbombal // SPONSORS // Interested in sponsoring my videos? Reach out to my team here: sponsors@davidbombal.com // MENU // 00:00 – Coming up 00:41 – Sponsored Section: KASM Workspaces demo 06:26 – Intro 06:46 – MJ’s Journey in OSINT 11:14 – Starting an OSINT Company 11:55 – Teaching Background 12:34 – Years in OSINT 13:19 – Advice for People Starting Out 15:44 – What It Means to Do OSINT 16:54 – Recommended Tools for OSINT 19:03 – Meet Ritu Gil 19:09 – Characteristics of a Good OSINT Investigator 20:03 – Knowing When to Give Up 20:43 – Soft Skills vs Technical Skills 22:17 – Ritu’s Advice on How to Get Started 23:24 – Are There Jobs in OSINT? 24:39 – Forensic OSINT Demo 26:41 – Tinder Vulnerabilities 30:51 – Next Guest Intro 32:04 – Rae Baker 32:33 – Tools Rae Uses 34:11 – From Graphic Design to OSINT 37:56 – Volunteering to Learn 39:10 – Next Guest Intro 40:10 – Eliot Higgins 40:19 – Eliot’s Background into OSINT 41:44 – Bellingcat 44:27 – No Degree Needed to Start 45:37 – Useful Tools to Use 47:19 – Advice for People Starting Out 48:36 – Communities to Join 51:50 – Recommended Books 53:03 – How MJ Got the Job 55:53 – MJ Shares an OSINT Story 01:02:44 – Importance of a Team 01:08:15 – Conclusion 01:10:34 – Outro osint open-source intelligence open source intelligence tools osint curious geolocation geolocation game facebook instagram google bing yandex geolocation google geolocation bing you cannot hide social media warning about social media google dorks dorks google osintgram osint framework osint tools osint tv osint ukraine osint tutorial osint course osint instagram osint framework tutorial cyber security information security open-source intelligence open source intelligence sans institute cybersecurity training cyber security training information security training what is osint open source artificial intelligence cyber hack privacy nsa oscp ceh Please note that links listed may be affiliate links and provide me with a small percentage/kickback should you use them to purchase any of the items listed or recommended. Thank you for supporting me and this channel! Disclaimer: This video is for educational purposes only. #osint#cyber#privacy
OSINT and BABEL STREET:
Description
OSINT, or Open Source Intelligence, is the process of collecting and analyzing publicly available information from various sources, such as websites, social media, news articles, and public records, to gain insights and intelligence. It’s used by organizations, including governments, businesses, and individuals, to understand threats, identify vulnerabilities, and make informed decisions.
What is Open-Source Intelligence?
Open-Source Intelligence (OSINT) is defined as intelligence produced by collecting, evaluating and analyzing publicly available information with the purpose of answering a specific intelligence question.
Information versus Intelligence
It’s important to note that information does not equal intelligence. Without giving meaning to the data we collect, open-source findings are considered raw data. It is only once this information is looked at from a critical thinking mindset and analyzed that it becomes intelligence.
For instance, conducting OSINT is not simply saving someone’s Facebook friends list. It’s about finding meaningful information that is applicable to the intelligence question and being able to provide actionable intelligence in support of an investigation. Another way to look at it is to answer, “why does this data matter” and provide meaningful intelligence about the data collected.
Open-source information is content that can be found from various sources such as:

• Public Records
• News media
• Libraries
• Social media platforms
• Images, Videos
• Websites
• The Dark web
Who uses OSINT?

• Government
• Law Enforcement
• Military
• Investigative journalists
• Human rights investigators
• Private Investigators
• Law firms
• Information Security
• Cyber Threat Intelligence
• Pen Testers
• Social Engineers
We all use open-source and probably don’t even realize it, but we also use it for different reasons. You might use open-source information to do a credibility check and to find out more about the person selling you something on Facebook marketplace. You may research someone you met on a dating app or before hiring someone for a job.
A few years ago I found someone’s driver’s license on the street when I was on a lunch break. I picked it up, thinking I should drop it off at the local driver’s license branch. Then I thought to myself, I wonder what I will find if I just Google the person’s name (which I did). Turns out the second Google result was a LinkedIn page with the person’s name, photo, and workplace which was in the area. I decided to call the company and ask to speak with this person and let them know I had found their license on the street.
It seems like it was too easy to Google and find the result quickly but this is not uncommon nowadays. Most people, if not everyone, have some sort of digital footprint. This is a simple example to show you how quickly you can find information on a person by simply Googling their name.
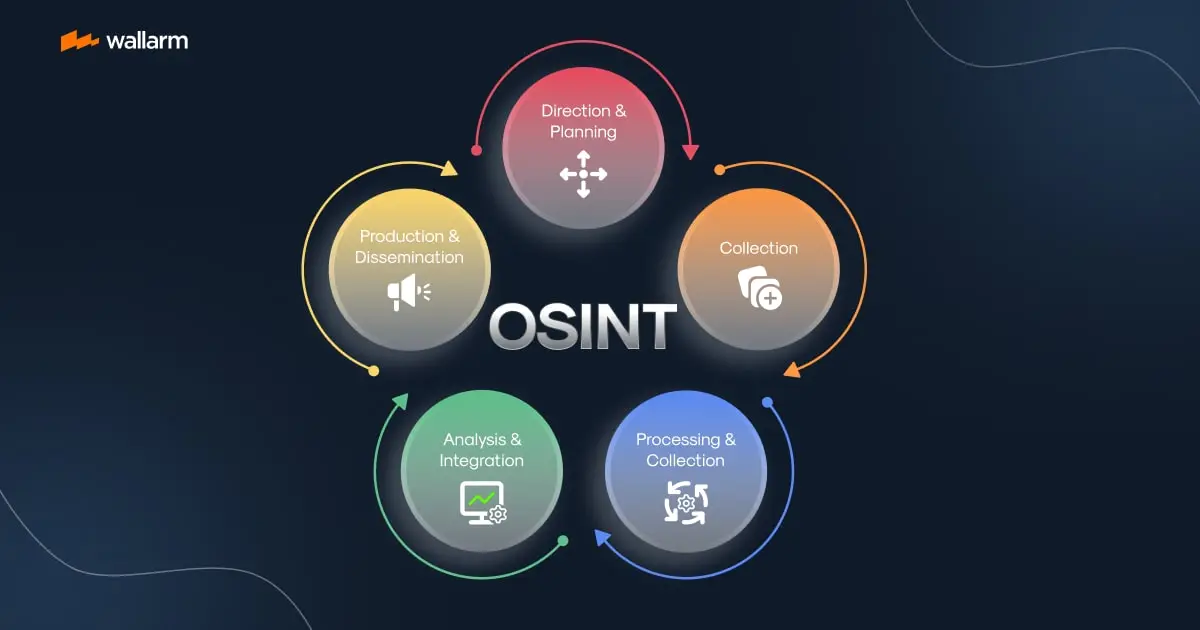
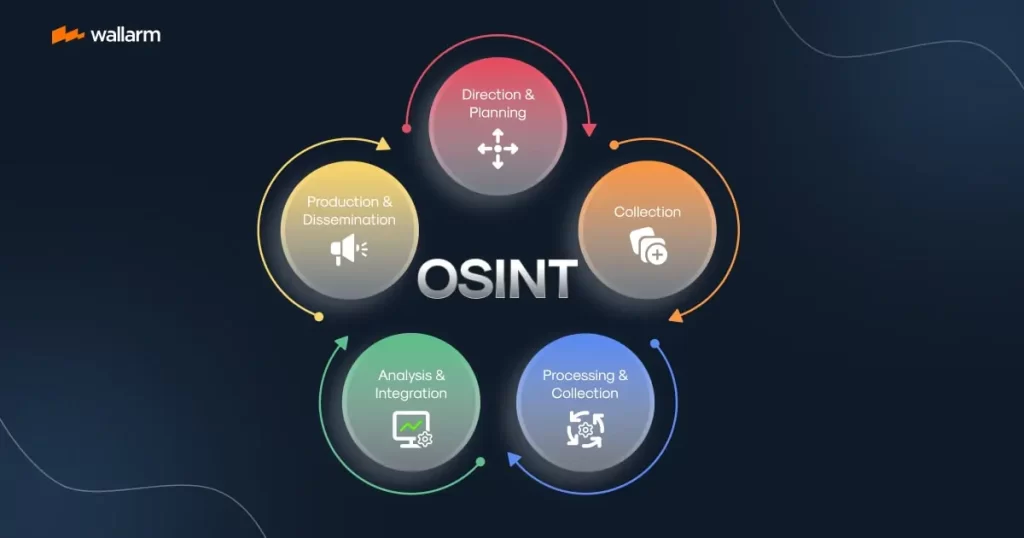
Intelligence Cycle
Let’s talk about the Intelligence Cycle and what it means for those working in OSINT. There are some variations of the intelligence cycle but generally, it includes similar steps. Using the Intelligence Cycle can assist with understanding what each stage of the cycle means to the OSINT research that will follow.
Stages of the Intelligence Cycle
Preparation is when the needs and requirements of the request are assessed, such as determining the objectives of the tasking and identifying the best sources to use to find the information for which you are looking.
Collection is the primary and most important step in collecting data and information from as many relevant sources as possible.
Processing is when the collected data and information are organized or collated.
Analysis and Production is the interpretation of the collected information to make sense of what was collected, i.e. identifying patterns or a timeline of travel history. Produce a report to answer the intelligence question, draw conclusions, and recommend next steps.
Disseminationis the presentation and delivery of open-source findings, i.e. written reports, timelines, recommendations, etc. Answer the intel question for stakeholders.
Passive versus Active OSINT
Understand the difference between passive and active research, as each type of research can have different implications for your organization.
Passive means you do not engage with a target. Passive open-source collection is defined as gathering information about a target using publicly available information. Passive means there will be no communicating or engaging with individuals online, which includes commenting, messaging, friending, and/or following.
Active means you are engaging with a target in some fashion, i.e. adding the target as a friend on social profiles, liking, commenting on the target’s social media posts, messaging the target, etc. Active open-source research is considered engagement and can be looked upon as an undercover operation for some organizations. Please be aware of the differences and request clarification from your agency prior to engaging.
For active research, it’s a must to blend in with the group. If you are engaging with a target you may want to create a couple of accounts on different platforms to make it look like you are a real person.
Each organization may have different interpretations of what is considered passive versus active engagement. For example, joining private Facebook Groups may appear passive to some organizations, whereas others may consider this as engaging. Sometimes this difference can imply some sort of undercover operation capacity, therefore it’s extremely important to have SOPs that outline where the organization stands with this type of engagement.
Some researchers justify joining groups as passive, as they are only “passively” looking and not actually communicating with targets.
A good example to consider is where a Facebook Group consists of 500 members or more, where blending in may be easy, whereas a smaller group of 20 people may be riskier. Talk to your managers before proceeding one way or the other.

How Is Open Source Intelligence Used?
Open Source Intelligence (OSINT) is the collection, analysis, and dissemination of information that is publicly available and legally accessible. Right now, OSINT is used by a organizations, including governments, businesses, and non-governmental organizations. It is useful in information gathering for a wide range of topics such as security threats, market research, and competitive intelligence.
Here are some common ways in which OSINT is used:
- Security and Intelligence: OSINT can be used to gather information on potential security threats, such as terrorist activity or cyberattacks. It can also be used for intelligence gathering on foreign governments, organizations, or individuals.
- Business and Market Research: OSINT can be used to gather information on competitors, industry trends, and consumer behavior. This information can be used to inform business strategy and decision-making.
- Investigative Journalism: OSINT can be used by journalists to gather information on a range of topics, including politics, business, and crime. This can help to uncover stories and provide evidence for reporting.
- Academic Research: OSINT can be used by researchers to gather data on a range of topics, including social trends, public opinion, and economic indicators.
- Legal Proceedings: OSINT can be used in legal proceedings to gather evidence or to conduct due diligence on potential witnesses or defendants.
OSINT is an exceptional tool for gathering information on a wide range of topics and can be used by a variety of organizations and individuals to inform decision-making and strategy.
Why Open-Source Intelligence (OSINT)?
Open-source intelligence (OSINT) is beneficial because it offers several advantages over other forms of intelligence collection.
Here are some reasons why OSINT is valuable:
- Access to publicly available information: OSINT collects publicly available and legally accessible information. This means that organizations do not have to rely on classified or restricted sources of information, which can be costly and time-consuming to get.
- Wide range of sources: OSINT can be gathered from a wide range of sources, including social media, news articles, government reports, and academic papers. Organizations can gather information on a wide range of topics from many different perspectives.
- Timeliness: Because OSINT relies on publicly available information, it can be gathered quickly and in real time. Organizations or businesses can stay up-to-date on current events and emerging trends.
- Cost-effective: OSINT is more cost-effective than other forms of intelligence collection, such as human intelligence or signal intelligence. This is because OSINT relies on publicly available information and does not require specialized equipment or personnel.
- Transparency: OSINT is transparent and can be easily verified. This means that organizations can be confident in the accuracy and reliability of the information they gather.
OSINT offers many advantages over other forms of intelligence collection, making it a valuable tool for a wide range of organizations and individuals.
How does open-source intelligence (OSINT) work?
Open-source intelligence (OSINT) is the practice of collecting and analyzing publicly available information to generate actionable intelligence. Here’s a general overview of how OSINT works:
- Collection: OSINT collection involves gathering publicly available information from a variety of sources such as social media, news articles, government reports, academic papers, and commercial databases. This process can be done manually by searching for and reviewing sources, or through automated tools that can search and aggregate information.
- Processing: Once the information is collected, it is processed to remove duplicate, irrelevant or inaccurate data. This step involves filtering and categorizing the information based on relevance and importance.
- Analysis: The processed information is then analyzed to identify trends, patterns, and relationships. This can involve using data visualization tools, data mining, and natural language processing to extract meaningful insights from the data.
- Dissemination: The final step in the OSINT process is disseminating the intelligence to decision-makers. This can be done in the form of reports, briefings, or alerts, depending on the needs of the organization.
OSINT is an iterative process that involves constantly refining the collection, processing, and analysis of information based on new data and feedback. Additionally, OSINT is subject to the same biases and limitations as other forms of intelligence collection, and therefore requires careful evaluation and interpretation by trained analysts.
Common OSINT techniques
Open-source intelligence (OSINT) encompasses a wide range of techniques for collecting and analyzing publicly available information. Here are some common OSINT techniques:
- Search Engines: Search engines such as Google, Bing, and Yahoo are valuable tools for gathering OSINT. By using advanced search operators, analysts can quickly filter and refine search results to find relevant information.
- Social Media: Social media platforms such as Twitter, Facebook, and LinkedIn are valuable sources of OSINT. By monitoring and analyzing social media activity, analysts can gain insight into trends, sentiment, and potential threats.
- Public Records: Public records such as court documents, property records, and business filings are valuable sources of OSINT. By accessing these records, analysts can gather information on individuals, organizations, and other entities.
- News Sources: News sources such as newspapers, magazines, and online news outlets are valuable sources of OSINT. By monitoring and analyzing news articles, analysts can gain insight into current events, trends, and potential threats.
- Web Scraping: Web scraping involves using software tools to extract data from websites. By scraping data from multiple websites, analysts can gather large amounts of data quickly and efficiently.
- Data Analysis Tools: Data analysis tools such as Excel, Tableau, and R are valuable for analyzing large datasets. By using these tools, analysts can identify patterns, trends, and relationships in the data.
OSINT techniques are constantly evolving as new technologies and sources of information become available. It’s important for analysts to stay up-to-date on new techniques and tools in order to effectively gather and analyze OSINT.
How OSINT can benefit your organization
- Support criminal investigations by providing background profiles on people and businesses
- Support human source assessments
- Support security/risk assessments
- Support decision making
- Assist with making associations between entities
- Provide situational awareness such as getting insight into current events
Learn more about OSINT by taking SEC497 Practical Open Source Intelligence (OSINT)
Learn more about OSINT Training
View more about OSINT Certification
Check out our SANS OSINT Resources
Check out our SANS OSINT Tools
Here’s a more detailed explanation:
Legal and Ethical:OSINT relies on publicly available information, making it a legal and ethical way to gather intelligence.
Open source intelligence (OSINT) is a form of intelligence collection management that involves finding, selecting, and acquiring information from publicly available sources and analyzing it to produce actionable intelligence. In the intelligence community (IC), the term “open” refers to overt, publicly available sources (as opposed to covert or classified sources); it is not necessarily related to open-source software or public intelligence.
Publicly Available Information:OSINT focuses on information that is freely accessible to the public and legal to obtain.
Diverse Sources:OSINT draws information from a wide range of sources, including online news, social media platforms, government websites, and even publicly available databases.
Analysis and Actionable Insights:The collected information is then analyzed to extract valuable insights and actionable intelligence.
Applications:OSINT is used for various purposes, including cybersecurity threat intelligence, competitive intelligence, market research, and even personal investigations.
For example, American military professionals have collected, translated, and studied articles, books, and periodicals to gain knowledge and understanding of foreign lands and armies for over 200 years. The recent exponential growth in computer technology and the Internet has placed more public information and processing power at the finger tips of military personnel and other users than at any time in the past. Internet sites (i.e., websites) enable global users to participate in publicly accessible communications networks that connect computers, computer networks, and organizational computer facilities around the world. Through use of the Internet, users can locate, monitor and observe various websites to obtain any quantity of useful information (e.g., in the case of the military, enemy intentions, capabilities, activities, etc.). To name only a few, websites of news outlets, television stations, forums, and the like may be monitored and/or searched for particular terms or topics of interest during such OSINT gathering.SUMMARY OF THE INVENTION
The speed of Internet activity has exceeded the pace of OSINT collection and analysis. As a result, open source intelligence gatherers have been presented with the basic trade-off of analysis quality versus production timeliness. Some existing systems merely collect an abundance of information and then leave it to the service subscribers to determine that which is of value. For instance, existing systems allow users to perform queries on one or more data sources and then return what may be thousands of results to the user based on the query parameters. Even valuable data collected in abundance presents the difficulty of amassing resources required to manually analyze the data for discovery of trends and anomalies of interest. However, many if not most of the results may be uninteresting to the user due to sub-optimal search engine technologies and automated collection processes.
Furthermore, much of the content making up a website or other data source and on which a query or analysis may be performed may be of a form that is not important to a user and/or which may skew search results and subsequent analyses. For instance, a particular page on nytimes.com including an article discussing the results of a recent major sporting event may also include a small advertisement directed to no fee checking with a major bank. As part of the same example, imagine a user interested in learning about any recent developments in relation to the loan fees charged by the World Bank to third world countries performs a search using any appropriate search tools utilizing the query parameters “world,” “bank,” “fees” and “loans.” As the New York Times article about the sporting event happens to include an advertisement directed to “no fee checking” with a “major bank,” the sporting article may be presented as one of the results to the user’s search query, much to the user’s dismay.
It has been determined that systems, apparatuses and methods (i.e., utilities) are needed that can both provide for automated, lightweight collection of online, open source data which may be content-based to reduce website source bias. In one aspect, a utility is disclosed for use in extracting content of interest from at least one website or other online data source (e.g., where the extracted content can be used in a subsequent query and/or analysis). Depending upon the particular objects or goals of a subsequent query or analysis, “interesting” content may be the actual text of a webpage (e.g., just the text of an article on the webpage, and not any text or other characters associated with advertisements or navigation sections). In another scenario, the interesting content may just be any HTML links (e.g., “inlinks”) contained within the article on the webpage. For instance, a user may be interested in news articles or blog postings that have inlinks to a particular URL. For purposes of this discussion, the terms “query,” “search,” “filter” and the like (along with their respective variations) will be used interchangeably.
The utility may include obtaining source code used to generate the at least one website on a display, where the source code includes a plurality of elements and each element includes at least one tag comprising at least one tag type; parsing the source code using a processor to obtain a node tree including a plurality of nodes arranged in a hierarchical structure, where each node comprises one of the elements, and wherein one of the plurality of nodes comprises a root node; determining a tag type of a node under the root node; assigning a heuristic score to the node based at least in part on the tag type of the node; repeating the determining and assigning for one or more additional nodes of the node tree; and generating, using the processor, an object that includes content associated with nodes of the node tree having heuristic scores indicating that such content is of interest.
This utility allows any desired content to be extracted from a piece of data (e.g., the source code of a webpage) with little or no prior knowledge of the page and with little or no human interaction. For instance, any appropriate server and/or process may collect large volumes of website data on a scheduled basis, utilize this utility to extract interesting content, and then index such content in a data store for subsequent searching and/or analysis. Furthermore, the various details of the originally observable webpage (e.g., graphics, advertisements, etc.) may also be available to a user (e.g., by storing such original data in the data store).
In addition to the aforementioned utilities that allow for automated and lightweight collection of online, open source data, it has also been determined that various utilities that provide analytic visualizations of such collected open source data are needed to, for instance, allow for trending and discovery of interesting and/or important developments and occurrences. For example, the various utilities disclosed herein can act as early warning systems for emerging sentiments and ideologies that are adverse to U.S. interests. In this regard, and in another aspect, a utility is disclosed that allows for the determination (e.g., automated determination) of a sentiment of a term among a plurality of data sets. For instance, a user may initially define a “scenario” made up of one or more keywords and operators (collectively, “scenario parameters”) that focus on attacks performed by Al Qaeda. The scenario may then be used to perform a query of online, open source data in any appropriate manner to obtain a number of search results (e.g., a list of relevant websites). In addition to the search results, the user may be benefited by visually observing a sentiment (e.g., positive, negative, neutral) of one or more terms (e.g., Osama Bin Laden) of the scenario parameters and/or terms that are frequently used throughout the returned results over one or more time periods.
In this regard, the utility includes receiving the x most frequently disclosed terms (e.g., top five, top ten) among a plurality of data sets (e.g., plurality of objects including content extracted from websites using the above-discussed utility) during a time period (e.g., day, week), where x is a positive integer; for each of the x most frequently disclosed terms during the time period: determining, using a processing engine, a volume of the plurality of data sites disclosing the term; and obtaining, using the processing engine, a sentiment of the term among the plurality of data sites; and presenting, on a display, a first graphical representation illustrating the sentiment and volume of each of the x most frequently disclosed terms during the time period.
That is, as opposed to a user manually selecting those words or terms for which to determine a sentiment, the disclosed utility may automatically select (e.g., based on frequency of use in the returned search results or in other appropriate manners) which terms to perform a sentiment analysis on, and then may present the results of such sentiment analysis on a display (e.g., in the form of sparkcharts or other graphical representations that display the sentiment over a selected time period). Advantageously, a user need not manually review the search results for terms on which to perform sentiment and volume analyses. Furthermore, a user may be more interested in reviewing sentiment/volume analyses for terms that are more frequently disclosed (i.e., other than terms like “a,” “or,” etc.) than other terms as the mere fact that the term is frequently disclosed may indicate a greater relative importance of the term in relation to other terms.
Furthermore, the posts or websites that contain the particular terms that are automatically selected by the utility may be the posts for which sentiment is determined. Stated otherwise, the text of those websites (i.e., their extracted content) where the particular terms are found may be the text that is used to determine if the overall sentiment of the term is positive, negative or neutral. For example, if a website where one of the particular terms (e.g., Mubarak) for which a sentiment analysis is being performed contains 30 instances of “hate” but only 5 instance of “like,” then the website may be labeled as a “negative” website/data site. A similar procedure may be performed on other websites of the search query results for the term Mubarak. Subsequently, an overall sentiment for the term Mubarak for a particular time period or time increment may be obtained by subtracting the number of “negative” sites where the term Mubarak is found from the number of “positive” sites where the term Mubarak is found to obtain a result, and then using the result to determine whether the term Mubarak should be indicated as having a positive, negative or neutral sentiment for the time increment/period. Other appropriate types of statistical analysis may be performed to obtain term sentiments as well.
In addition to the sentiment, the utility may also automatically determine a volume of use of such terms and additionally present graphical representations of such volumes on the display (e.g., alongside and/or integrated with the determined sentiments). Furthermore, the utility may allow for the manual and/or automatic selection of what will be referred to as “stop words,” that is, words or terms that would not be used as part of the sentiment/volume analysis, even if such words were, for instance, one of the most frequently used words in the search query results (e.g., “a,” “the,” etc.).
In another aspect, a utility for creating a hierarchical signature for a website or other online data source is disclosed that can allow a user to, for instance, discern the ebb and flow of topics over any appropriate time period on individual websites as well as on automatically clustered sites (e.g., using any appropriate clustering methods or processes) that have similar signatures. More specifically, a “signature” of a website or other online data source may be obtained by determining a frequency or prevalence of particular terms on one or more pages of the website over a time period, and then appropriately presenting such signature on a display for visualization by a user. For instance, a frequency of each of the terms “counterterror,” “government,” “military,” and “president” on each of a number of websites (e.g., those websites returned corresponding to a particular scenario) may be determined, the results may be normalized to “high,” “medium” and “low,” and then such normalized results may be presented for a user on a display in the form of a color coded chart (e.g., where darker colors represent higher frequency and lighter colors represent lower frequency). This utility may allow such signatures to be leveraged to track discussions, infer textual linkages among websites, discover communities of interest according to topic saliency, and the like.
This utility involves identifying at least one textual hierarchy including at least first and second levels, where the first level comprises at least one textual category and the second level comprises at least one term that describes the at least one textual category; determining a number of occurrences of the at least one term from a number of pages of at least one website during a time period; first obtaining, using a processing engine, a hierarchical signature of the at least one term that represents a prevalence of the at least one term on the at least one website; second obtaining, from the first obtaining step, a hierarchical signature of the at least one textual category that represents a prevalence of the at least one textual category on the at least one website; establishing a hierarchical signature of the at least one website utilizing the hierarchical signature of one or more of the at least one term and the at least one textual category; and presenting, on a display, a graphical representation of the hierarchical signature of the at least one website, where the graphical representation illustrates the prevalence of one or more of the at least one term and the at least one textual category.
Of note, this utility not only obtains a hierarchical signature of one or more terms for one or more websites (by determining a prevalence of such terms on such websites), but also obtains a “first level” signature of a category that represents or encompasses the one or more terms by, for instance, averaging (and/or performing other appropriate types of statistical analyses) the “second level” hierarchical signature(s) of the one or more terms. For instance, a “communications” category could be manually and/or automatically made up of the terms “audio,” “propaganda,” “statement,” and “video”. Numerous other categories could be manually and/or automatically determined (e.g., “government,” “Congress”). In this regard, a “first level” hierarchical signature of a website may be made up of the particular frequencies of a number of categories and may be presented on a display in the form of, for instance, a number of adjacent graphical icons, where a color of each graphical icon represents the prevalence of one of the categories on the website. Furthermore, a “second level” hierarchical signature of a website may be made up of the particular frequencies of the terms making up one or more of the aforementioned categories on the website (e.g., in the case of the category “communications,” the terms “audio,” “propaganda,” “statement,” and “video”).
The at least one textual hierarchy in this utility which forms the basis of the hierarchical signature determination may be identified in any appropriate way (e.g., manually, automatically). In one arrangement, scenario parameters used to perform a query that turned up the at least one website for which the hierarchical signature is being determined may be at least partially used in the textual hierarchy (e.g., as first-level categories and/or second-level terms). In another arrangement, a number of default categories with respective terms may be defined and which may be manually selected by a user as part of an analysis of search results. In a further arrangement, one or more “community” of “network” signatures may be determined. For instance, any appropriate standard tools or algorithms may be used to determine one or more communities of interest from the results of an open source search query (e.g., each community including a plurality of websites or online data sources having one or more common traits or characteristics, such as a number of websites taking a particular view of an important world event). The disclosed utility may then “roll up” or otherwise combine the “site signatures” (e.g, made up of first and/or second level signatures) of each of the websites to obtain a “community signature”.
In another aspect, a utility is disclosed for use in inferring an information flow network that can allow information flows between and among websites and authors to be determined over time. The utility can capture relationships between people and entities in online discussion environments (e.g., forums, blogs) and enable a network of relationships between entities that are discussing topics of interest to be discovered and “verified” automatically. For instance, the utility can build connections by way of analyzing metrics such as frequency of posts or postings (e.g., blog entries), frequency of responses, context of posts, and the like to enhance identification of significant relationships.
The utility includes receiving information related to a plurality of portions of source code used to generate a plurality of online data sources (e.g., blog postings, news articles, web pages, etc), where the information allows a uniform resource locator (URL) to be obtained for at least one of the data sources; determining, from the information using a processor, whether any of the plurality of online data sources refers to another online data source during a first of a plurality of time periods (e.g., days), where any online data source that refers to another online data source comprises a “secondary data source”, and where any online data source that is referred to by another online data source comprises a “primary data source”; in response to at least some of the plurality of online data sources referring to other online data sources, obtaining, from the information, a unique URL for each of the primary and secondary data sources; repeating the determining and obtaining for additional time periods; and presenting, on a display, a graphical representation of an information flow network that illustrates one or more information flow links connecting and representing information flows from primary data sources to secondary data sources over the plurality of time periods.
For instance, in the context of a news article on nytimes.com discussing President Obama’s new education agenda that includes an HTML link to whitehouse.gov in the body of the article, the graphical representation may include a graphical icon representing the primary data source URL “whitehouse.gov,” another graphical icon representing the secondary data source URL “nytimes.com,” and another graphical icon (e.g., an arrow) representing an information flow from the whitehouse.gov icon to the nytime.com icon. In other words, the information flow may be determined by “reversing the inlinks” disposed within a particular online data source. In one arrangement, the source code corresponding to the primary and secondary data source URLs may have been previously harvested utilizing any appropriate search engine(s) and/or process(es) and stored in one or more data stores for retrieval by the utility.
In one arrangement, unique URLs may be constructed for online data sources. For instance, as each posting on a blog site has the same URL or IP address (i.e., the URL or IP address of the blog site), it may otherwise be difficult to establish online information flow networks and thereby map information flows among a number of postings. In this regard, one embodiment involves constructing a unique URL for each posting of a blog site (or other online data source) by utilizing the URL of the blog site or website along with one or more identifiers of or associated with the individual posting as inputs to any appropriate algorithm or logic operable to generate or create a unique URL for the particular posting.
In another arrangement, the utility may further include, in response to a user manipulable device or component (e.g., cursor, user’s finger) being positioned over a primary data source graphical icon (e.g., the whitehouse.gov icon discussed above), modifying a feature of the primary data source graphical icon (e.g., to assume a first color), modifying a feature of any secondary data source graphical icons of the primary data source graphical icon (e.g., modifying the nytimes.com icon discussed above to a second color), and modifying a feature of the information flow link graphical icons connecting the primary data source graphical icons and the secondary data source graphical icons (e.g., to a third color). For instance, the three colors may be different from the colors of other graphical icons in the graphical representation of the online information flow network to allow a user visually observe the particular manner in which a particular post/blog entry affects or is affected by information flows in the network.
In another aspect, a utility is disclosed for use in extracting content of interest from a collection of webpages. This utility can limit off-topic or low value portions of the webpages from being extracted for use in subsequent analyses and manipulation. The utility includes acquiring source code used to generate each webpage of a collection of webpages on a display; obtaining a similarity matrix for the collection of webpages from the acquired source code using a text-based similarity measure; using the similarity matrix to determine a maximum dissimilarity score for each webpage in relation to the collection of webpages using a processor; and presenting, on a display, one or more lists of those webpages associated with maximum dissimilarity scores above a threshold dissimilarity score. For instance, the objects may be arranged in the one or more lists according to date of publication of the webpage associated with the object. Advantageously, a timeline may present objects (e.g., posts) in a manner that provides a particular breadth of coverage for each of a number of time periods (e.g., for each day of a particular time range). That is, the timeline may present a user with a variety of posts each day, all of which are encompassed within the parameters of a particular scenario, sub-scenario, etc. This arrangement allows a user or users to discover the full range of discussions for a particular scenario that may have been missed by a manual analysis owing to the sheer volume of popular topics.
The utility may also include first extracting a first portion of content from the source code of a first webpage of the collection of webpages using a first set of inquiries; first determining, for the extracted first portion of the first webpage, a maximum similarity score in relation to the similarity matrix using a processor; and generating an object with the extracted first portion responsive to the maximum similarity score being greater than a first threshold similarity score.
In the event that the maximum similarity score is not greater than a first threshold similarity score, the utility includes second extracting from the source code of the first webpage a second portion of content using a second set of inquiries different than the first set of inquiries, and second determining, for the extracted second portion of the first webpage, a maximum similarity score in relation to the similarity matrix using the processor. For instance, the first set of inquiries can be adjusted (e.g., adding or editing at least one inquiry) so that a second portion of content is extracted from the source code that is different than the first portion.
In one arrangement, the various steps of the utility (e.g., the first extracting, first determining, generating, and, if necessary, the second extracting and second determining) can be repeated for the source code of additional webpages of the collection of webpages to obtain a first group of objects corresponding to a plurality of extracted portions. Thereafter, a second group of objects may be obtained from the first group of objects, where the second group of objects is associated with extracted portions having maximum similarity scores above a second threshold similarity score that is greater than the first threshold similarity score.
In another aspect, a utility is provided for use in automatically extracting a textual hierarchy from one or more webpages of a website for use in creating a hierarchical signature for the website. Advantageously, this utility may substantially generate one or more textual hierarchies and may be used as an alternative to and/or at least partially in conjunction with the manual selection of one or more portions of one or more textual hierarchies. The utility includes receiving the x most frequently disclosed terms among one or more pages of a website, where x is a positive integer; first clustering, using a processor, the x most frequently disclosed terms into two or more sets of terms as a function of semantic similarity between the terms in each subset; second clustering, using the processor, the two or more sets of terms into two or more subsets of terms utilizing contextual information located proximate each of the terms, where each of the terms in the subsets comprises a lower level term; and ascertaining, for each of the two or more subsets, an upper level term that semantically encompasses each of the lower level terms in the subset.
As examples, the first clustering could include agglomerative clustering, the second clustering may utilize at least one of a bag-of-words model and Dice’s coefficient, the contextual information for each term may include a window of adjacent terms around the term, and/or the ascertaining may include finding a deepest common root in a general purpose ontology including the lower level terms of the subset. In any case, one embodiment envisions determining a prevalence of each of the lower level terms on the one or more pages of the website to obtain hierarchical signatures of the lower level terms; using the hierarchical signatures of the lower level terms to establish hierarchical signatures for each of the upper level terms; and presenting, on a display, a graphical representation of a hierarchical signature of the website, where the hierarchical signature of the website include the hierarchical signatures of the upper level terms.
In another aspect, a utility is provided for use in determining an influence of sentiment expressed in a post of an author of an online information flow network on the posts of one or more other authors in the network. For instance, the determined sentiment influences of the various posts and/or authors of the information flow network may be used to determine one or more “online roles” for the various authors of the network (e.g., such as provocateurs). This utility includes receiving information related to a plurality of online posts, wherein each of the online posts is associated with at least one author; obtaining, from the information, a listing of online posts that refer to one or more other online posts, wherein any online post that refers to another online post comprises a “secondary post” and wherein any online post that is referred to by another online post comprises a “primary post”; building an information flow network that includes a plurality of information flow links that connect and represent information flows from primary posts to secondary posts; first determining, using a processor, a sentiment of each of a primary post and one or more secondary posts of the primary post; second determining, using the processor, a sentiment influence of the at least one author of the primary post in the information flow network using the sentiment of the primary post and one or more secondary posts; and presenting, on a display, a graphical representation of the sentiment influence of the at least one author of the primary post in the information flow network.
In one arrangement, the second determining may include determining a first average sentiment of the one or more secondary posts; determining a second average sentiment of other posts in the information flow network initiated by the at least one author of the primary post; and determining a quotient of the first average sentiment and the second average sentiment to obtain the sentiment influence of the at least one author of the primary post in the information flow network. For instance, the primary post, one or more secondary posts, and other posts in the information flow network associated with the at least one author of the primary post relate to a common topic or discussion. Any appropriate manner of normalizing the post sentiments may be utilized. For instance, the post sentiments may be normalized by way of identifying a quantity of at least one of positively or negatively charged terms in the post; identifying a total number of terms in the post; and dividing the quantity of the at least one of positively or negatively charged terms in the post by the total number of terms in the post to obtain a normalized sentiment of the post.
The various aspects discussed herein may be implemented via any appropriate number and/or type of platforms, modules, processors, memory, etc., each of which may be embodied in hardware, software, firmware, middleware, and the like. Various refinements may exist of the features noted in relation to the various aspects. Further features may also be incorporated in the various aspects. These refinements and additional features may exist individually or in any combination, and various features of the aspects may be combined. In addition to the exemplary aspects and embodiments described above, further aspects and embodiments will become apparent by reference to the drawings and by study of the following descriptions.
Cryptocurrency system using body activity data
https://patents.google.com/patent/WO2020060606A1/en
https://patentscope.wipo.int/search/en/WO2020060606
https://patents.google.com/patent/US6754472B1/en
ethods and apparatus for distributing power and data to devices coupled to the human body are described. The human body is used as a conductive medium, e.g., a bus, over which power and/or data is distributed. Power is distributed by coupling a power source to the human body via a first set of electrodes. One or more devise to be powered, e.g., peripheral devices, are also coupled to the human body via additional sets of electrodes. The devices may be, e.g., a speaker, display, watch, keyboard, etc. A pulsed DC signal or AC signal may be used as the power source. By using multiple power supply signals of differing frequencies, different devices can be selectively powered. Digital data and/or other information signals, e.g., audio signals, can be modulated on the power signal using frequency and/or amplitude modulation techniques.
Images (7)







Classifications
H04Q9/04 Arrangements for synchronous operation
View 1 more classifications
Landscapes
Engineering & Computer ScienceComputer Networks & Wireless Communication
Show more
US6754472B1
United States
Download PDF Find Prior Art SimilarInventorLyndsay WilliamsWilliam VablaisSteven N. BathicheCurrent Assignee Microsoft Technology Licensing LLC
Worldwide applications
Application US09/559,746 events
2000-04-27Application filed by Microsoft Corp
2000-04-27Priority to US09/559,746
2004-06-22
Application granted
2004-06-22Publication of US6754472B1
2020-04-27
Anticipated expiration
Status
Expired – Lifetime
Show all events
InfoPatent citations (15)Non-patent citations (12)Cited by (181)Legal eventsSimilar documentsPriority and Related ApplicationsExternal linksUSPTOUSPTO PatentCenterUSPTO AssignmentEspacenetGlobal DossierDiscuss
Description
FIELD OF THE INVENTION
The present invention relates to methods and apparatus for transmitting power and data, and more particularly, to methods of powering devices coupled to the human body and communication information between the devices.BACKGROUND OF THE INVENTION
Small portable electronic devices are commonplace today. Small portable devices commonly used by people today include wristwatches, radios, communications devices, e.g., pagers and cell phones, and personal data assistants (PDAs) to name but a few exemplary devices. As electronics manufacturing techniques have improved, weight and power consumption requirements of many small portable devices have decreased. At the same time, the capabilities of the devices have increased. As a result, it is now possible to power many small electronic devices including watches, audio players, personal data assistants, portable computers, etc. with relatively little power.
Given the small size and portable nature of many of today’s portable electronic devices, people have begun wearing them on their bodies. For example, wristwatches are worn on people’s arms, pagers and PDAs are worn on people’s belts, and small displays are sometimes worn mounted on headgear.
As a result of carrying multiple portable electronic devices, there is often a significant amount of redundancy in terms of input/output devices included in the portable devices used by a single person. For example, a watch, pager, PDA and radio may all include a speaker. In order to reduce the redundancy in input/output devices, networking of portable electronic devices has been proposed. By exchanging data, e.g., as part of a network, a single data input or output device can be used by multiple portable devices, eliminating the need for each of the portable devices to have the same input/output device.
Various approaches have been taken in an attempt to network portable devices. The uses of radio (RF) signals, infrared (IR) communications signals, and near field intrabody communication signals are examples of various signals that have been suggested for use in networking portable devices. Radio signals between devices can cause interference. In addition radio devices can be expensive to implement and tend to consume relatively large amounts of power. In addition, decoding another person’s transmitted information and controlling another person’s device is plausible using RF, raising the concern for security and privacy. IR communications signals present similar privacy concerns to those of RF signals while further being subject to additional limitations in terms of the tendency for many objects, e.g., opaque objects, to block the transmission of IR signals. Near field intrabody communication signals represent a relatively new and still largely undeveloped field of signal communications.
In the case of one near field intrabody communications system, information is exchanged between electronic devices on or near the human body by capacitively coupling picoamp currents through the human body of a person.
While some work has been done to minimize the redundancy that exists in data input/output devices, in portable devices frequently used by a single individual, there still remains room for improvements in the way information is communicated between portable devices. In addition, some wearable devices are not big enough to have any kind of interface at all; e.g. earrings.
There remains significant room for improvement with regard to how portable devices are powered. Portable electronic devices frequently rely on power supplied by batteries to operate. Batteries have a limited energy storage capability. As a result, batteries periodically need to be replaced or, assuming they are rechargeable, recharged. The need to replace or recharge batteries posses a serious limitation on known portable battery powered devices. Battery replacement normally involves physically removing a current set of batteries and replacing them with a new set of batteries. Recharging of batteries normally involves plugging the portable device into a battery charger thereby limiting the devices portability until the re-charging is complete or, alternatively, swapping a charged battery pack for a battery pack including the batteries, which need to be recharged.
The swapping of battery packs, replacement of batteries, and/or recharging of batteries by plugging in a portable device represents an inconvenience in terms of time involved with a user performing a battery replacement operation or recharging operation. In many cases it also represents an interruption in service, i.e., often during the battery swapping or recharging operation, the device cannot be used or its portability is limited.
Until the present invention, the focus with regard to portable device power issues has been largely on improving the quality of batteries, reducing the amount of power required by a portable device to operate, and/or in providing backup power sources, e.g., to permit the swapping of batteries without causing an interruption in operation.
While recent improvements in batteries and device power consumption has increased the amount of time portable devices can operate before needing the batteries to be recharged or replaced, the need to periodically recharge or replace batteries in portable devices remains an area where improvements can be made. In particular, there is a need for making recharging of batteries easier to perform, preferably without requiring an interruption in device operation or for backup batteries inside the device. There is also a need for eliminating batteries in at least some portable devices, thereby reducing the weight of the portable devices making them easier to wear for extended periods of time.SUMMARY OF THE PRESENT INVENTION
The present invention is directed to methods and apparatus for distributing power to devices coupled to the human body. The invention is also directed to methods and apparatus for communicating information, e.g., data and control signals, to devices coupled to the human body.
In accordance with the present invention the human body is used as a conductive medium, e.g., a bus, over which power is distributed. Information, e.g., data and control signals, may also be distributed over the human body in accordance with the present invention. To avoid the need for digital circuitry, e.g., in audio output devices, some of the communicated signals may be analog signals. For example, analog audio signals may be transmitted to a speaker using the human body as the communications media by which the audio signal is transmitted.
In accordance with the invention, power is distributed by coupling a power source to the human body via a first set of electrodes. One or more devices to be powered, e.g., peripheral devices, are also coupled to the human body via additional sets of electrodes. The devices may be, e.g., a speaker, display, watch, keyboard, etc. A pulsed DC signal or AC signal may be used as the power source. By using multiple power supply signals of differing frequencies, different devices can be selectively powered. For example, a 100 Hz signal may be used to power a first device while a 150 Hz signal may be used to power a second device. Digital data and/or other information signals, e.g., audio signals, can be modulated on the power signal using frequency and/or amplitude modulation techniques. The power source and peripheral devices can interact to form a complete computer network where the body serves as the bus coupling the devices together. Devices can include optional batteries, one or more CPUs, transmit/receive circuitry, and/or input/output circuitry. In one particular exemplary network implementation the first device to be placed on the body operates as a master device, e.g., bus master, with subsequently added devices working as slaves. In accordance with the invention power and/or communication signals may also be transmitted from one body to another by touch.
The proposed methods of the present invention enable the use of a whole new class of wearable devices. These devices do not have a direct interface, but are instead used as relays for collecting and transmitting information to the user. For example earrings, which can be used to measure the persons pulse rate or even deliver sound to the ear via a phone worn on the person’s belt. To program the earring directly would be a quite cumbersome task; however, the earrings parameters could be set via another device that is large enough and has the appropriate user interface to enter data. The user could use this device to control the volume of the earrings or to control other function of this device. This concept could be extended to many other such devices that are worn on the body: jewelry, watches, and eyeglasses to name a few.
Because the devices of the present invention are networked, they can be recharged and powered by other devices on the network. Kinetic to power converters can be used in this network to sustain this network’s power. Kinetic converters in shoes and on wrist watches can be used to convert the kinetic energy of the user to electrical power and distribute that power to the rest of the network. This is yet another property that distinguishes devices of the present invention from other networks such as RF or IR.
Numerous additional features and advantages of the present invention will be discussed in the detailed description, which follows.BRIEF DESCRIPTION OF THE DRAWINGS
FIG. 1 illustrates an exemplary system of the present invention wherein the body of a person is used as a bus for distributing power and information between various devices coupled to the person’s body.
FIG. 2 is a block diagram illustration of the exemplary system illustrated in FIG. 1.
FIG. 3 illustrates two of the devices shown in FIG. 2 in greater detail.
FIG. 4 illustrates an exemplary portable device implemented in accordance with the present invention.
FIG. 5 illustrates the contents memory included in a communications/power module implemented in accordance with the present invention.
FIG. 6 illustrates device circuitry, which may be used to implement a portable computer system coupled to a body in accordance with the present invention.DETAILED DESCRIPTION
As discussed above, the present invention is directed to methods and apparatus for distributing power to devices coupled to the human body. The invention is also directed to methods and apparatus for communicating information, e.g., data and control signals, to devices coupled to the human body.
FIG. 1 illustrates a system
10 implemented in accordance with the present invention. The system
10 comprises a plurality of portable devices
20, 22, 24, 26, 28, 32, and 30, which are coupled together by the human body
11. The portable devices include a portable computer device
20, a pager device
22, a keyboard
24, a display
26, an audio input device
28, an audio playback device
30 and a power supply
While the above system has been described as a network of devices coupled to a single body it is to be recognized that the network can be extended by connecting multiple bodies through physical contact, e.g., touching hands as part of a handshake. When two or more bodies are connected physically, the linked bodies form one large bus over which power and/or communications signals can be transmitted.
In addition, the physical resistance offered by the human body can be used in implementing a keypad or other input device as well as estimating distances between devices and device locations. In accordance with the present invention, by varying the distance on the skin between the contacts corresponding to different keys, different signal values can be generated representing different inputs.
The relative distances between devices coupled to a body can be estimated based on the strength of a device’s transmit signals as compare to the strength of the receive signals detected by a device. If the location of the master device is known, then the master can estimate the location of peripherals on the body. This information is used in accordance with various embodiments of the present invention by the communications/control device logic when controlling the power of broadcasted signals. Broadcast signal power is reduced when the device to which the signal is being transmitted is in close proximity to the broadcasting signal source and increased when the device is relatively distant from the broadcasting signal source. Thus power usage can be optimized to minimize wastage. In one particular embodiment, the voltage of a signal transmitted by a first device and received by a second device over a body is measured by the second device to determine the strength of the received signal. The output voltage and/or duty cycle of signals transmitted from the second device to the first device are then adjusted as a function of the measured signal voltage. The power control circuit
68 of a portable device is used to perform the received signal voltage measurement and to control the output voltage/duty cycle control operation. To perform these function the control circuit
68 may include voltage measurement circuitry, e.g., volt meter, and control logic. Normally a low measured voltage, indicative of a relatively large distance between the first and second devices, will result in the second device transmitting a signal to the first device with a higher output voltage or duty cycle than when a higher voltage is measured in regard to a signal received from the first device.
In accordance with another feature of the present invention, devices can initialize differently depending on location. For example, a speaker located near the ear can convey its location so that it will be supplied with less power than a speaker further away from the ear, e.g., a speaker located on the waist or arm. Accordingly, the transmission of device location information as part of a device initialization process that occurs after a device is placed on the body is contemplated and implemented in various exemplary embodiments.
Various exemplary embodiments have been described above. In view of the description provided above, various modifications will be apparent to those skilled in the art without deviating from the inventive teachings described and claimed herein. For example, it will be apparent that the body may be that of a wide variety of living animals and need not be limited to being a body of a human being.
Unlocking the Power of Public Information Harvesting (OSINT)
In general terms, Open Source Intelligence (OSINT) primarily concerns the collection, analysis, and comprehension of freely accessible information. The reservoirs for such knowledge could encompass virtual communal spaces, press firms, government archives, scholarly materials, and others. The potency of OSINT resides in its capacity to derive significant insights and facts, which prove beneficial for varying objectives, from safeguarding digital landscapes to market research.
A distinguishing attribute of OSINT is its unrestricted nature. Unlike other intelligence gathering methods that require specialized equipment or permissions for proprietary data access, OSINT leverages freely available data for any internet-user. This unconstrained access renders it an exceptional asset for both institutions and individuals, regardless of their size.
OSINT, through its versatility, emerges distinctively. It facilitates the collation of details on a variety of topics, ranging from imminent digital threats to recent market dynamics. It is due to this adaptability that it assumes a vital role for diverse professionals, from online safety specialists to market researchers.
Furthermore, the economic viability of OSINT is a compelling element. Primarily operating on public data significantly curtails or even removes financial costs, marking it as the perfect alternative for new ventures or small businesses that lack investments for high-end information-collecting methods.
Despite its benefits, the massive amount of accessible data for OSINT brings its unique set of challenges. The enormous information terrain can be daunting for many, unsure about where to initiate. Here, specific techniques and instruments can be beneficial to navigate the terrain.
For instance, web-scraping tools can facilitate automated data collection from websites, while text analytics software can help unearth recurring themes or trends in large data clusters. These instruments can considerably enhance the efficiency of OSINT tasks.
As a practical scenario, consider the following Python code that uses the ‘Beautiful Soup’ library for web data extraction:
from bs4 import BeautifulSoup
import requests
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))
In this snippet, we employ the requests.get() function to send a GET request to the assigned URL. Subsequently, the ‘Beautiful Soup’ library processes the response and prints all the webpage links.

In summary, OSINT acts as a powerful asset providing crucial insights and facts. Through the use of publicly disseminated data, individuals and organizations alike can gain a critical edge in our current era dominated by information. However, mastering OSINT truly comes to fruition when one acquires the knack to proficiently collect, examine and comprehend this communal data. Let’s continue our exploration in the forthcoming : “Unlocking the Cybersecurity World with OSINT.”
Influential Footprints of Open Source Investigation in Cybersecurity Evolution
The cybernetic cosmos gets significantly characterized by Open Source Investigation (OSI), a fundamental pillar which employs widely accessible data for an intelligence backdrop. As we explore the second chapter, we will dive deep into the particular ways through which OSI moulds the proficient landscape of cybersecurity.
The Twosome: OSI and Cybersecurity in the Information Age

We live in a virtual eon where information is supreme. Amid an avalanche of data, the decisions tend to lean towards enlightenment, which is strikingly evident in the sphere of cybersecurity. OSI unveils a profusion of details, instrumental in exposing upcoming hazards, examining vulnerabilities, and framing effective defensive tactics.
Consider a basic example: A cyber analyst avails OSI for extracting insights regarding an IP address that is flagged suspicious. Through the application of tools like IP specific explorer, the analyst can identify the legal possessor of the questionable IP address, its geolocation, and additional pertinent details. Equipped with this package of data, they can anticipate possible danger and react accordingly.
OSI Resources: The Lifeline of Cybersecurity
The horizon for gathering OSI data offers a sundry of resources. The range traverses from regular internet search engines such as Google to specialized tools like Shodan, indexing devices hooked to the internet. Let’s draw a brief comparison of commonly used OSI tools:
| Tools | Operation | Application |
|---|---|---|
| Universal search on the internet | Gathering info on individuals, companies, etc. | |
| Shodan | Exploring internet-connected gadgets | Spot unprotected devices. |
| IP Detail Examiner | Info on IP/Domain | Identify questionable IP addresses. |
| Online Buzz Tracker | Social media scan | Monitor brand referrals, sentiment analysis. |
Such resources, among several others, lay the groundwork for building OSI. Proper utilization of these tools can gift cybersecurity experts with exhaustive details, strengthening security endeavors.
Witness OSI in Action: A Real-life Situation
To gain clarity on how OSI shapes the cybersecurity blueprint, let’s ponder over a legitimate scenario. Suppose an organization is targeted in a phishing operation. The culprits circulate emails to workers, tricking them into forfeiting login credentials.
In this predicament, OSI can be leveraged in multiple ways:
- Domain Examination: By using platforms like IP Detail Examiner, the safety division can extract information about the domain applied in the phishing emails, aiding in tracing attackers, maybe locating their base.
- Social Media Surveillance: Tools like Online Buzz Tracker can be engaged to sift through social media for discussions linked to the phishing campaign. Such advance intel can warn of impending attacks and enable the organization to respond swiftly.
- Hazard Vision: Integrating information derived from myriad OSI tools, the safety unit can sketch a holistic figure of the threat milieu, aiding in the devising of powerful defensive tactics and averting prospective assaults.
Deciphering the Legal Considerations of OSI
As great an asset OSI is for cybersecurity, mindfulness of its legal implications is indispensable. In general, amassing data that is publicly accessible is within rights. But, manipulating that data maliciously or procuring it obsessively may land one into legal complications. It’s mandatory to ensure that use of OSI aligns with all essential laws and protocol.
The Final Word
OSI stands central in designing the cybersecurity universe. It caters to security professionals with a wealth of easily obtainable data, facilitating the detection of threats, the examination of weaknesses, and the generation of beneficial defense tactics. Just like any equipment, it ought to be used sensibly and legally. With a future-facing perspective, the influence of OSI in cybersecurity is set to become more prominent.
Key Instruments for Excelling in the Open Source Intelligence (OSINT) Landscape
Open Source Intelligence (OSINT), when leveraged correctly, can be invaluable to cybersecurity analysts, digital investigators, and regulatory bodies alike. However, its power can be more effectively harnessed with the right resources at your disposal. Hence, this section aims to illuminate the vital instruments needed to conquer the OSINT world, outlining their functionalities, applications and advantages.
Google Dorks
Imagine a search methodology that employs refined operators on the Google search platform to pinpoint precise data – that’s Google Dorks. It is particularly potent within the OSINT realm as it reveals concealed information that might otherwise go unnoticed.
# A Google Dork search instance
site:example.com filetype:pdf
The above instruction samples for PDF documents within the ‘example.com’ domain. Significantly, Google Dorks could uncover potentially exposed sensitive data, encompassing, but not limited to, classified documents, electronic mail addresses, and possibly password documents.
Shodan
Frequently labelled as a “search facilitator for the Internet of Things (IoT)”, Shodan is a crucial asset in the OSINT sphere. It enables users to identify specific classes of computers plugged into the internet via a host of filters.
# A Shodan search instance
shodan search --fields ip_str,port,org,hostnames Microsoft IIS 6.0
The aforementioned command prompts a search for servers running Microsoft IIS 6.0, disclosing details such as IP addresses, ports, company, and hostnames.
Maltego
The data extraction software, Maltego, offers interactive diagrams for link scrutiny. It is exceptional for creating visual depictions of intricate networks and relationships across individuals, corporations, or larger bodies.
# A Maltego transform instance
maltego.Person("John Doe").get_transform("ToEmail")
The command above locates all email handles connected with “John Doe”.
Contrast Table: Google Dorks vs. Shodan vs. Maltego
| Instrument | Pros | Cons |
|---|---|---|
| Google Dorks | Robust search abilities, easy to navigate | Restrained to information indexed by Google |
| Shodan | Broad IoT search abilities, elaborate findings | Commands a grasp of specific search syntax |
| Maltego | Ideal for constructing complex network visuals | Could be difficult to operate, necessitates training |
TheHarvester
TheHarvester is an indispensable OSINT utility for accumulating unmanaged email accounts, subsidiary domain tags, virtual hosts, open ports/ banners, and employee databases from various public sources.
# TheHarvester search instance
theharvester -d example.com -b google
The above function samples for data connected to ‘example.com’, utilizing Google as the data vendor.
Recon-ng
As a comprehensive web exploration framework, Recon-ng is essentially a force multiplier for web-dependent open source intelligence.
# A Recon-ng command instance
recon/contacts-credentials/hibp_breach
The command outlined will prompt a search for any data compromise connected to the target.
An array of several instrumentalities exists out there for accelerating your OSINT proficiency. Each of these tools carries a unique set of strengths and drawbacks. The tool chosen inevitably depends on the exact demands of the job in question. By assimilating these tools into your tactics, your OSINT expertise can be greatly refined, leading to a more robust cybersecurity defence mechanism.
Leveraging Open Source Data for Boosting Cybersecurity
Tapping into the reservoir of information that is freely available to one and all, often referred to as Open Source Intelligence (OSINT), significantly amplifies your protection measures against cyber threats. This treasure of facts, sourced from various public fields, endows you with critical perspectives about possible cyber hazards and areas of vulnerability. This section will delve into methods to exploit OSINT to strengthen your online bulwark.
Exposing Conceivable Dangers and Vulnerabilities
OSINT acts as a spyglass to expose potential dangers and frailties in your network design. Continuous monitoring of interconnected spaces such as chat forums and social media bestows knowledge about emerging hacking techniques, software threats, and possible weak points in systems.
Take, for instance, counter-intelligence strategies could encompass the use of OSINT tools to probe hacker interaction mediums and spot any reference to your organization. If a cyber offender is planning an attack or identifies a crack in your systems, such detection may provide a timely caution.
# Python demo code to probe a forum for references to
your organization
import requests
from bs4 import BeautifulSoup
def scrutinize_forum(forum_url, organization_name):
retort = requests.get(forum_url)
broth_bowl = BeautifulSoup(retort.text, 'html.parser')
notices = broth_bowl.find_all('notice')
for notice in notices:
if organization_name in notice.text:
print(f"Potential hazard identified: {notice.text}")
Enhancing Incident Handling
In the wake of a security mishap, OSINT takes on added significance. After a breakthrough, OSINT could be harnessed to accumulate particulars about the invader’s approaches, antecedents, and possible associations with other malign activities.
For instance, at the happening of a DDoS attack, OSINT facilities can aid in tracking down the origin, identify the culprits IP details, and amass information about the assailant’s plans and aims.
Boosting Security Awareness and Advancement
OSINT utilities can be put to effective use to elevate the level of security acumen and skill development within your cadre. By bringing to light real instances of security threats, OSINT can help comprehend the import of cybersecurity and the techniques to fortify your operations and data.
For example, related episodes of common cyber attacks could be accumulated via OSINT and used as case studies during your team’s training gatherings.
Carrying Out Competitive Surveillance
Lastly, OSINT can be of assistance in conducting stealthy observation of your competitors. By tracking your adversaries’ online conduct, you can comprehend their strategies, strengths, and blunders, and leverage this knowledge for honing your cybersecurity arrangements.
As an illustration, keeping track of a rival’s social media actions for mentions of security breaches or infringements could offer insights into their weak points and help you foresee threats relevant to your enterprise.
In conclusion, OSINT stands as a powerful reservoir that significantly spruces up your cyber defense programs. By leveraging OSINT, you can sniff out vulnerabilities, augment breach handling, amplify security comprehension and training, and undertake competitive scrutiny. However, it’s pivotal to remember that OSINT is merely one tool in your cybersecurity armory, and ought to be employed in conjunction alongside other defensive techniques for effectual protection of your digital wealth and information.
Maximizing the Potential of Community-based Intel in Contemporary Digital Evidentiary Research
Indisputably, Community-Sourced Information or CSI, is increasingly gaining ground. Its pivotal and often neglected contribution to digital forensics is indisputable. The exhaustive pool of information it comprises can enhance inquiries into cyber felonies, assist in unmasking cyber misbehaviors, and fortify our efforts in ensuring digital safety. This section aims to shed light on the instrumental role that CSI plays in the evolving panorama of digital forensics, concentrating on its connotations, usage, and the substantial advantages it yields.
The Influential Role of CSI in the Area of Digital Evidentiary Research
Considering the surging occurrences of cyber anomalies in our progressively digitized world, the need for digital evidentiary research as an independent field has surged. This variegated field encompasses the stages of collecting digital pieces of evidence, safeguarding them, examining them, and presenting them. Amid this process, CSI emerges as a tactical device, offering a plethora of information that can demystify the complex mazes of cyber events.
The significance of CSI in the domain of digital forensics can be highlighted as follows:
- Data Amplification: CSI provides a capability to spawn a considerable quantity of data from various public forums. These involve social networking arenas, digital doors, website statistics, conversational platforms, and data repositories. Such information forms the investigative foundation of all cybercrime probes, delivering insights into clandestine operations.
- Real-time Data Reaping: CSI infrastructures have the aptitude to efficiently reap data contemporaneously. This trait is beneficial in immediately trailing digital offenders and addressing cyber misdeeds promptly.
- Budget-friendly Efficiency: As CSI utilizes readily accessible public data, it proposes an economical approach for information gathering.
Utilization of CSI in Digital Forensics
CSI has pragmatic usability across a variety of areas in digital forensics:
- Scrutiny of Cyber Violations: CSI unveils priceless specifics about cyber lawbreakers, their secretive actions, and methodologies. These findings expedite the investigative procedures and assist in the dispensation of justice.
- Threat Recognition: CSI aids in aggregating critical awareness about forthcoming cyber threats, enabling companies to enhance their digital defensive strategies.
- Acquisition of Digital Authentication: CSI competencies can unearth digital authentication from an extensive assortment of sources. This validation can be presented in a court of law to support or oppose a contention.
The Gains of Integrating CSI in Digital Forensics
Implementing CSI within the scope of digital evidentiary research proffers several benefits:
- Improved Inquiry: The exhaustive information from CSI allows comprehensive investigations. It enables forensic experts to unearth hidden details and connections that might otherwise stay veiled.
- Advanced Cybersecurity: By providing data on probable hazards, CSI aids companies in bolstering their digital protective measures.
- Legally Compliant: As CSI peruses public data, it typically adheres to legal requirements. Nonetheless, the information should always be handled in a manner considerate of privacy laws and standards.
To conclude, the influence of CSI on contemporary digital evidentiary research is significant. Its comprehensive information assists in improving cyber inquiries, fortifying digital safety, and assembling digital validation. As our digitized surroundings persistently transform, the relevance of CSI within digital forensics will progressively intensify.
Understanding Legal Aspects of Collating Publicly Accessible Data
Harnessing the power of Publicly Obtainable Data Collection (PODC), in terms of consolidating, analyzing, and decision-making, provides a considerable strategy. Yet, it is paramount for PODC practitioners to recognize potential legal repercussions that could surface from its practice. This chapter delves deep into the legalities linked to PODC, encapsulating laws surrounding privacy, data protection mandates, and ethical standards for operational conduct.
Respecting Privacy Protocols in PODC Implementation
In the context of PODC deployment, privacy laws are a primary legal concern. These regulations are multifaceted and differ regionally and even within the confines of a single country. A case in point is the U.S.’s Fourth Amendment which safeguards its citizens from unwarranted searches and seizures; amassing data devoid of a legal warrant or person’s consent could be deemed illegal.
Importantly, it is worth mentioning that PODC primarily focuses on harvesting information that is publicly accessible. This implies that lawfully, PODC experts can amass data from online resources open to the public, public records, and similar platforms. The difficulty exists in defining what falls under ‘public’ data, with ambiguous areas often encountered.
Understanding Data Protection Policies
Another significant legal factor is data security policies. These laws intent to ensure data confidentiality and reliability by outlining procedures relevant to data aggregation, storage, utilization, and distribution.
An exceptional privacy legislation is the Personal Information Security and Electronic Documentation Act (PISEDA), introduced by Canada, which formulates strict regulations for data collection and utilization. In conformance with PISEDA, explicit approval from individuals is required before their data is collected, with a mandatory full disclosure on how this data will be utilized.
From the PODC viewpoint, it implies that publicly accessible information regarding Canadian citizens has to be managed in compliance with PISEDA. Breaching these regulations could invite severe penalties.
Navigating Ethical Quandaries
Alongside deliberating on legal repercussions, potential ethical predicaments instigated by PODC utilization also demand consideration. A legal allowance doesn’t automatically equate to ethical approval, inferring that some data amassing practices may spark ethical debates.
For instance, collecting personal details from social media platforms, despite being legally allowed, may stir up ethical disputes. The question of whether utilizing this publicly shared information, despite it being lawful, aligns with ethical norms needs careful contemplation and prudent decision-making.
Legal Implications of Utilizing PODC Tools
There is a broad roster of tools that support PODC, ranging from basic online data extraction applications to sophisticated data analysis platforms. Each tool presents its own set of legal ponderings.
Data extraction tools, often utilized to collect substantial data efficiently, still, several websites incorporate restrictions against such extraction in their user agreements. Breaching these terms could provoke legal ramifications.
Moreover, some data analysis platforms might employ patented methodologies or formulas. Unauthorized use of these could instigate a copyright infringement lawsuit.
In conclusion, the potency of PODC isn’t shielded from potential legal ramifications. Therefore, any PODC user must display a pronounced cognizance of these possible legal and ethical implications and undertake the necessary actions to ensure that their practices align with both legal and ethical norms. This engenders profound comprehension and abidance by privacy and data protection laws, thoughtful reflection on ethical issues, and awareness of the legal risks attached to specific PODC tools.
Recognizing Evolving Progressions in the Universe of Publicly Available Knowledge Analysis (PAKA)
Navigating the evolving contours of Publicly Available Knowledge Analysis (PAKA), makes it evident that we are traversing an everchanging landscape. Rapid technologic advancements melding with a burgeoning influx of accessible information, are forging new horizons and obstacles for experts in PAKA’s realm. Here are some vital shifts altering PAKA’s direction:
Deploying Cognitive Computing and Data-Based Learning in Publicly Available Knowledge Analysis
Arguably the forerunners of novel technological breakthroughs – Cognitive Computing (CC) and Data-Based Learning (DBL) are witnessing an expanded role within the domain of PAKA. These pioneer technologies are central to refining the mechanisms for information selection and inspection, thereby empowering PAKA experts to excavate valuable revelations.
For instance, CC could be utilized to sift through voluminous text data, distinguishing patterns and developing trends, potentially challenging for humans to recognize manually. Conversely, DBL could be manoeuvred to train algorithms to single out a specific type of data, such as personal identifiers, residential locations, or financial card details.
An elementary instance showcasing how Data-Based Learning algorithms can be applied to categorize text data is presented below:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# Initialize a CountVectorizer object
vectorizer = CountVectorizer()
# Create a MultinomialNB object
clf = MultinomialNB()
# School the classifier
clf.fit(vectorizer.fit_transform(X_train), y_train)
# Forecast the labels of the test set
y_pred = clf.predict(vectorizer.transform(X_test))
Fusing PAKA with Variant Intelligence Categories
An emerging trait in PAKA’s expanse is the integration of publicly available knowledge analysis with other intelligence forms like Human Sourced Intel (HUMINT), Electronic Signal Intel (ESINT), and Geographic Coordinate Intel (GEOCINT). This cumulative approach offers a comprehensive perception of the security outlook, equipping practitioners to reach informed verdicts.
Surge in the Pertinence of Digital Interaction Platforms and Internet Sources
The ascendancy of digital interaction platforms and other internet sources as influential repositories of publicly available knowledge cannot be overlooked. The abundant cache of data available on these platforms is a potential trove for PAKA objectives, encompassing entries and dialogues to endorsement indices and transferred content. PAKA experts, however, need to carefully wade through this data deluge and distil the chunks of information pertinent to their stipulations.
Safety Queries and Legal Limitations
With a growing dependency on PAKA, concerns regarding privacy protection and the legal ramifications of collecting and exploiting publicly available information are becoming pressing issues. We can foresee an upswing in governing directives and guidelines aimed at protecting the privacy entitlements of persons and corporates.
Evolving Tools and Techniques in PAKA
The spectrum of PAKA’s future will mark the emergence of sophistically enhanced equipment and methodologies for data acknowledgement and interpretation. These may cover innovative algorithms for data prospecting, enhanced strategies for emotional response analysis, and advanced data representation skills.
In closing, Publicly Available Knowledge Analysis (PAKA) is gearing up for an exciting journey ahead, with an array of intriguing developments expected. As the wheel of technology spins forward, we can anticipate the advent of fresh tools and practices which will ease the burden of collecting and deciphering publicly available information for practitioners. It is crucial, however, that the field also counteracts the tribulations presented by privacy issues and resulting legal impediments.
See Wallarm in action
“Wallarm really protects our service and provides good visibility and user-friendly control.”